Lab 5: ANTLR parser generator
This lab is due at 2359 on Wednesday, 4 October. It should be submitted to the course SI413 as Lab05, with the files named properly according to the lab instructions. See the submit page for details. You are highly encouraged to submit whatever you have done by the end of this lab time. Remember that you must thoroughly test your code; the tests that are visible before the deadline are only there to make sure you are using the right names and input/output formats.
1 Starter Code
You should already have a shared git repository parsing.
To get the starter code for today's lab, cd to your
si413/parsing directory and run these commands:
git pull starter main
git pullYou should now have a folder like
si413/parsing/lab05
with the starter code for this lab, the
lab05.md file you will need to fill out,
and a handy script to submit your code.
You can also browse the starter code from the Gitlab page (USNA intranet only).
2 Overview
This lab is going to be pretty similar in scope to last week's lab: you're going to start by making a parser for the pat language, and then you're going to add functionality to make your parser actually interpret the language itself.
The big difference is that for this week's lab, rather than "hand-rolling" everything ourselves, we will use ANTLR to do the hard work for us.
ANTLR (www.antlr.org) is a powerful and widely-used tool for automatic scanner and parser generation. The idea is that you write down your scanner specs (token names and regular expressions) and grammar specs (nonterminal names and production rules), and leave it to ANTLR to actually deal with turning source code into a parse tree.
Then separately, you can write a class to recursively visit nodes in the parse tree and actually interpret the language.
This has a few benefits for us. First of all, it reduces the chance of making mistakes in the details of parsing, since we can just write down the scannar and grammar rules and rely on ANTLR to get the details right to create a parse tree. A second benefit is that we move towards separating the syntax specification from the language semantics in the interpreter. (Unlike last week's lab where the parsing and interpreting is all happening simultaneously in the same methods.)
Using a powerful library like ANTLR can involve some pain. Furthermore, because ANTLR itself generates java source code for the lexer and parser, we have to make sure this gets mixed in correctly with our own code.
Rather than trying to deal with these painful things ourselves, we will do it "the right way" and use another tool called Maven (maven.apache.org) to handle downloading dependencies, running ANTLR, mixing the code together, compiling it, and even running it. Getting used to Maven of course can also be a little uncomfortable as we get started, but this is the most widely-used tool for packaging real Java projects and it's worth our time to get comfortable using such tools.
There are four main phases of the lab:
- Download the tools and get yourself acquainted with ANTLR and Maven
- Complete the lexer and grammar specifications for the Pat langauge so that valid Pat programs parse correctly and invalid Pat programs don't.
- Simplify the grammar (and resulting parse trees) to mostly use a single non-terminal seq.
-
Complete the
PatEvaluatorclass to actually interpret the parse tree according to the semantics of the Pat language.
3 Getting started with mvn and ANTLR
3.1 Installation
If you are on a lab machine, you should already have what you need. On your laptop VM or WSL, run these commands on an Ubuntu command line to install Apache maven:
roche@ubuntu$sudo apt updateroche@ubuntu$sudo apt install maven
Notice that we did not install ANTLR here. That is because Maven "knows" about ANTLR, and will automatically download ANTLR (as well as a whole bunch of other stuff) the first time we ask maven to compile something.
3.2 Understanding Maven file structure
Maven is based on directories (similar to git).
On the command line, go into your starter code directory for
this lab now, and run tree to see a visual layout
of all the files and folders in the starter code.
You should see a few things:
-
pom.xml: This is the all-important configuration file that tells Maven everything about your Java project, including the names and all the dependencies.
Fortunately I've already written this for you. Feel free to look around if you are curious! -
runmain.shandruntest.share helper bash scripts to run some common mvn commands. More on these later. -
src/is a directory containing all of the source code for this Java project. The sub-directory structure is dictated by Maven and is very important. The important things are in three places:-
src/main/antlr4/si413/pat/contains the ANTLR specifications for the Pat scanner and parser that you will have to complete first.
When you compile using maven, it uses ANTLR to turn any.g4files in this directory into Java source code (which it puts in a completely different directory), and then those are mixed in with the rest of the Java source code and sent along tojavac. -
src/main/java/si413/pat/contains the rest of the Java source code. There are a few useful things we are giving you here. The most crucial file for you to modify isPatEvaluator.javawhich you will complete to get your interpreter working in the last part of the lab. -
src/test/java/si413/pat/contains JUnit5 unit tests. The test that we are giving you are exactly the same as the "public" tests you will see when you submit. Maven helps us run the unit tests too; see below.
-
To emphasize again, the directory structure is key! Maven works by looking for certain kinds of files in very particular directories. If you follow what we have, then Maven will automatically find the code you write.
Notice that everything is in some subdirectory .../si413/pat.
That matches the Java package for the code you write in this lab, which is
si413.pat.
This mostly means that we have to write package si413.pat; at the top
of any .java source code files.
(In prior courses, you probably did not have to specify the package of your own Java files, but more "serious" Java projects are always put into a package name, to make them easier to share with others and to get along with other existing code you want to use.)
3.3 Using mvn
The command-line for Maven is just mvn.
You have to run mvn from the top-level directory where your pom.xml file is.
Similarly to git, you specify what you want to actually do with sub-commands.
Here are the most important ones for us:
mvn compile- Yep, it compiles all your code.mvn test- Runs any and all JUnit tests.mvn exec:java -Dexec.mainClass=si413.pat.FancyInterpreter- Runs themain()method in the given class. (You could replaceFancyInterpreterwith any other class that has amain.)mvn clean- Removes any compiled stuff. (Sometimes useful but usually not needed.)
Try running mvn compile right now. It probably has to
download a bunch of stuff the first time, but it should work!
Maven gives a lot of output when you run it on the command-line. To ease your eyes for running your code and testing it, we have included two helper scripts:
runmain.sh MAINCLASS: Runs the named class, which should have amainmethod. Try doing this:
That should start the colorized pat interpreter (which mostly doesn't work because you haven't completed the lab yet!).roche@ubuntu$./runmain.sh FancyInterpreterruntest.sh TESTCLASS: Runs the JUnit tests in the named class. Try this, which will run the public tests for part 1 of the lab (which should mostly be failing since you haven't done it yet):
That still actually gives a lot of error output. You can clean it up and really just see the test results by running it like this instead:roche@ubuntu$./runtest.sh Part1Testroche@ubuntu$./runtest.sh Part1Test 2>/dev/null
4 Parsing pat
Recall the token and grammar specifications for the Pat language from the previous lab:
SYM: [a-z][a-zA-Z0-9]* FOLD: "*" STOP: ";" COLON: ":" NAME: [A-Z][a-zA-Z0-9]* REV: "_r" LB: "[" RB: "]"
prog → seq STOP prog | EOF
seq → seq FOLD catseq | catseq
catseq → catseq opseq | opseq
opseq → opseq COLON NAME | opseq REV | atom
atom → SYM | NAME | LB seq RB
Your task is to complete the ANTLR specifications in
PatLexer.g4 and PatParser.g4 for the
Pat language as indicated above.
Hint: Look back at the two files ACalcLexer.g4 and ACalcParser.g4 from the Unit 4 notes for example of what the ANTLR syntax is for regular expressions and grammar rules.
To test what you have for this part, you can use the provided FancyInterpreter, which (with the starter code) will just say "Parse OK" when each statement correctly parses, and otherwise relays the ANTLR error explaining why parsing didn't work. For example:
roche@ubuntu$./runmain.sh FancyInterpreterpat>one two three;Parse OKpat>[who can it]_r:BE now;Parse OKpat>lucy in the * sky with * diamonds;Parse OKpat>unmatched ];ERROR: ERROR in PatParser on line 1 column 10: extraneous input ']' expecting ';'pat>bad letter ? yeah no question marks here;ERROR: ERROR in PatLexer on line 1 column 11: token recognition error at: '?'
You can also run the unit tests for this part via:
roche@ubuntu$./runtest.sh Part1Test
Exercises
-
Complete the
PatLexer.g4
and PatParser.g4
files (in directory src/main/antlr4/si413/pat/)
so that the Pat language parses correctly.
5 Simplifying the grammar
PatLexer.g4
and PatParser.g4
files (in directory src/main/antlr4/si413/pat/)
so that the Pat language parses correctly.
The grammar above works and is un-ambigious. However, it has a lot of "extra" rules like opseq and atom that specify precedence and associativity, but don't really specify any extra meaning.
The provided main method in ShowParse.java
(feel free to have a look!) will display the parse
tree for any Pat program you type in.
Check out the parse tree for a small program by running
./runmain.sh ShowParsea b c;
followed by Ctrl-D.
You should see a big tall parse tree pop up. Look over it carefully! You should see how this is dictated exactly by the grammar specified above for the Pat language.
Your task for this part is to simplify the grammar so that it has only two non-terminals, prog and seq. Bascially what this means is that many of those other non-terminals will be replaced by seq, and some of the trivial rules will just go away.
The goal is to simplify the grammar so that the same
small Pat program a b c; can have a much
smaller, easier-to-deal-with parse tree, that looks
exactly like this:
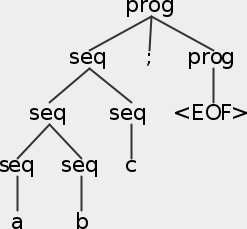
Note: be careful not to mess up the precedence!
Your new grammar will technically be ambigious, but ANTLR
allows this and simply follows a "greedy" approach to
resolve ambiguity, where the first right-hand-side in the
grammar that can match a given expansion, is the one that
is taken. So you want higher-precedence operators in the Pat
language, to appear higher up in the PatParser.g4
file.
To check your work, the best way is to run ShowParse,
try many different (valid) Pat language inputs, and confirm
that the parse tree has the correct precedence etc.
I suggest starting with very small Pat programs and working your
way up to more complicated ones, like
a;
one two;
concatenation after reversal_r;
two left * two right;
...You can also run the unit tests for this part via:
roche@ubuntu$./runtest.sh Part2Test
Exercises
-
Change the grammar in
ParParser.g4
so that it only has two non-terminals, prog
and seq, WITHOUT changing the language itself
and WITHOUT changing the operator precedence and
associativity.
6 Interpreting pat
ParParser.g4
so that it only has two non-terminals, prog
and seq, WITHOUT changing the language itself
and WITHOUT changing the operator precedence and
associativity.
Now let's actually interpret the Pat programs you've been parsing!
Unlike with the previous lab where we wrote the parser ourselves and embedded the execution inside the parser logic, with ANTLR the two will be separate: first we parse the input according to the grammar rules, and second we use the resulting parse tree to actually execute the Pat program.
The way this works in ANTLR is to create an subclass of
PatParserBaseVisitor<T>,
where the T is replaced by whatever type of thing each parse
tree expression should produce. In this case, it should be
List<String> since that is what each
Pat sequence is.
Fortunately this is already started for you in the
PatEvaluator class. You just need to complete it
with (many) more methods for each type of seq node
in your parse tree.
Each one of the visit methods you write will look a lot like the recursive descent interpreter methods that you did for the last part of the previous lab, but with a key difference: you don't have to make parsing decisions using look-ahead because ANTLR has already done that for you!
Rather than me specifying here exactly how the visitor methods work, it will be much easier for you to instead have a look at the example in AntlrCalcEvaluator.java and AntlrCalcEvaluator.java from the Unit 4 notes. Make sure you understand that example!
In a nutshell, there are two things that need to happen for each possible right-hand side in your grammar.
- First, you need to annotate each possible right-hand side expansion
of a nonterminal in the
.g4grammar file like# Symbollike you see in the starter code. This is not just a meaningless comment - it tells ANTLR the name of that right-hand side expansion to refer to. - Then, in your
PatEvaluator.javafile, you have to add new methods for each right-hand side. You can see the ones forNonEmptyProgandSymbolare already written for you. If in doubt, you can find the base class that ANTLR generates automatically attarget/generated-sources/antlr4/si413/pat/PatParserBaseVisitor.javaDo not edit this file directoy, but use it as a guide for what methods you need to override in your ownPatEvaluatorclass.
Within each method you have to make recursive calls tovisit(...)for any children of that node in the parse tree, then use those results to return whatever the current node is supposed to return.
Feel free to also refer to the posted solutions from the previous lab for help.
As with last week, I recommend starting very small. A single symbol is already written for you; maybe try to incorporate concatenation next (and then test!), then reversing (then test!), etc.
To test your work on this part, just run the FancyInterpreter.
You will want to change the part in PatEvaluator
where it prints "Parse OK" to actually display the list of symbols
that results from that line of the program.
You can also run the unit tests for this part via:
roche@ubuntu$./runtest.sh Part3Test
Exercises
-
Complete
PatEvaluator.java
(in the folder src/main/java/si413/pat/) so that
Pat programs execute correctly.
PatEvaluator.java
(in the folder src/main/java/si413/pat/) so that
Pat programs execute correctly.