Lab 8: Treaps
- Due before 23:59 Wednesday, October 19
- Submit using the submit program
as
301 lab 08.
1 Random BSTs
One thing we don't have much time to touch on in this course is the often-surprising positive benefits of inserting randomness into a data structure or algorithm. However, it turns out that sometimes, by using randomness, we can create a solution which is almost certainly a good one.
BSTs are a good example of this. We know from our experience that there is a worst case for BSTs, where our data comes in in-order or nearly in-order, which can make the data structure pretty ineffective. However, if this case doesn't happen, our BST is probably pretty short! In fact, it turns out that if you have your sequence of inputs, and insert them in a random order, we can be almost certain that our tree will have height which is \(O(\log n)\).
One interpretation of this is that all the self-balancing trees out there are a waste of time, because we will almost certainly be fine with just a BST. However, this is incorrect. Data oftentimes isn't inserted in a random order; our project from Project 2, where we are working off an alphabetic list, is a good example. In other words, IF the data comes in randomly, we're almost certainly OK, but it usually doesn't! Therefore, learning data structures which can handle these cases is important.
To use this property, therefore, we need either a self-balancing tree, or a tree which builds itself as if the data had been entered in a random order. In the first case, we know the tree is balanced, but it may be hard to implement. In the second, we are extremely confident, though not completely confident, that the tree is balanced enough, and it may be simpler to implement. That may be a fair trade!
2 Treaps
Treaps (we'll explain the name more in a week or so) are one way of doing this. In a treap, each node has a data point and a priority. We maintain the BST property that small data points are to the left, and large data points are to the right, as well as the property that parents have larger priority than their children.
Upon insertion, the data point is assigned a random priority. It is then inserted as in a normal BST. Finally, rotations are performed until the "large-priorities-on-top" property is fulfilled. Let's see an example. We're going to insert numbers in increasing order (the worst case for BSTs, as we know, as well as an extremely common thing to encounter in the real world).
Normally, the random priorities assigned are real numbers between 0 and 1; this makes is nearly impossible for two nodes to be assigned identical priorities. However, for our example, we're going to use integers, since it's easier to read. The big number is the data, and the smaller number is the randomly-assigned priority.
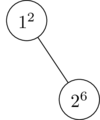
First we insert our 1, and it is given a random priority of 2:

Easy enough. Now we insert our 2, and it is given a random priority of 6. Because 6 is bigger than 2, we perform a rotation to maintain the heap property:
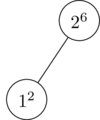
Now we insert a 3, and it is given a random priority of 5. 5 is less than 6, so no rotation is necessary.
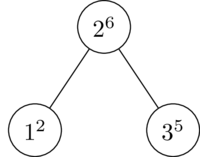
Now we insert a 4, and it is given a random priority of 3. 3 is less than 5, so again, no rotation is necessary.
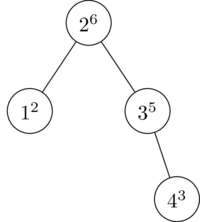
Now we insert a 5, and it is given a random priority of 4. 4 is larger than 3, so we perform a rotation to maintain the heap property.
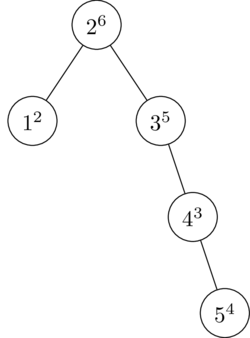
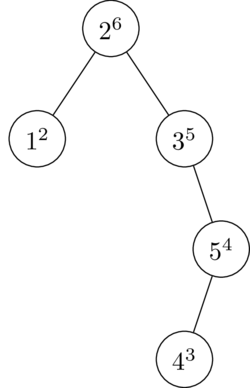
Finally, we insert a 6, with priority 1. No rotation is necessary.
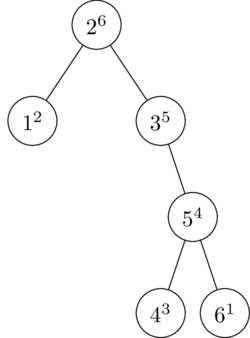
Now, is this the shortest possible tree? Of course not. But it is shorter than the equivalent BST is.
More interestingly, note that if we had inserted this data into a standard BST in order of decreasing priority (2,3,5,4,1,6), we would have ended up with exactly the same tree. Now, the priorities were assigned completely randomly. This means that the tree we get is equivalent to first doing a random permutation of the data, and then inserting in the new, random order! And we know if we did that first, we would probably get a \(O(\log n)\) height tree. Because a treap is equivalent to doing that, treaps are almost certainly \(O(\log n)\) height!
Finally, we note that there is no way for an adversary to design an input to our insert function that he knew would cause us problems. There is a worst case, but because of the randomness, there is no way to intentionally achieve it; we would have to be extraordinarily unlucky.
This isn't the only randomized data structure or algorithm out there, by any means, but it will be the only one we see this semester.
3 The Assignment
Important: This lab is unusual in that it's really the first part of what you need to do for Project 2. I'm giving you this lab time to work on it, but this means you need to be a little more careful and follow the project rules for this lab. Namely, the work you do must be your own and you can't look at each other's code directly. Also keep in mind that I will not be posting solutions for this lab right away next week as I normally would.
The actual assignment is pretty simple: implement a TreapMap. You'll turn in a
file called treap.py, with a class called TreapMap (and,
yes, a Node class as well). That Treap will have the same Map methods
__setitem__, __getitem__, __contains__,
and __len__
as last week's lab.
In fact, this will look quite similar to the BSTMap except that
(1) your Node class needs to have an additional field for the
randomly-chosen priority, and (2) after inserting something new in __setitem__,
you have to write the code to do the necessary tree rotations according
to the randomly-chosen priority of the new node.
Besides those methods, I also want you to write a method height(self)
that runs in \(O(n)\) time and computes the height of the treap. This is largely for yourself
to make sure your treap is working correctly. For example, if you insert 1000 items into the
treap and then print out the height, like
1 2 3 4 5 | t = TreapMap() for k in range(1000): t[k] = "" print(len(t)) # should print 1000 print(t.height()) |
the resulting height should be around 20 (but will vary a little bit every time because of the randomness!), and this whole loop should execute instantaneously. If you kick the size up to 1 million, the resulting height should be around 50 and it should take less than a minute to do this loop.
Once you finish, proceed with Project 2!