Unit 9: Graph search
Beginning of Class 31
1 Dijkstra's Algorithm
BFS works great at finding shortest paths if we assume that all edges are equal, because it minimizes the number of "hops" from the starting point to any destination. But in a weighted graph, we care about the total sum of the weights along any candidate path, and want to miminize that value rather than the number of hops. In other words, it's OK to take more turns in your driving directions, as long as the total time is less.
Consider the following graph. Here, the vertices may be intersections, and the edges may be roads, with expected time to travel as the weights.
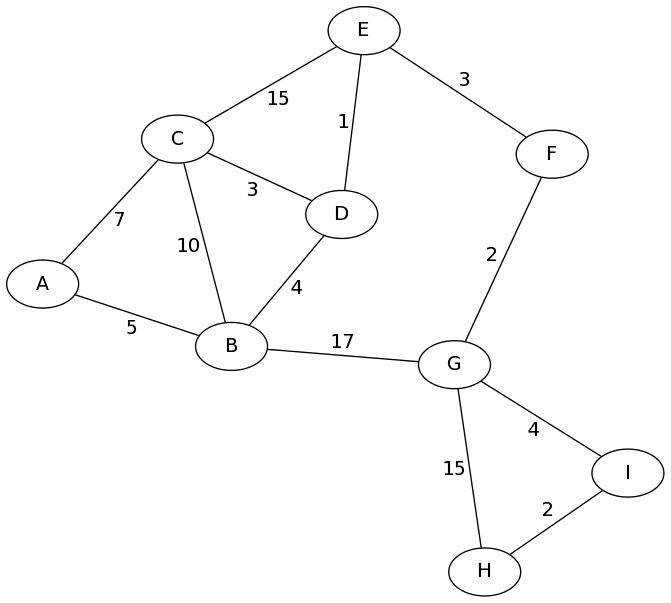
Let's consider the problem of finding the fastest route from vertex A to
vertex H. A BFS would find us a path with the minimum number of hops, perhaps
A - B - G - H. This path "looks" shortest, but it has total
length \(5+17+15 = 37\) in the graph. There is definitely a shorter way!
The good news is that we only really have to change one thing to adapt our BFS to work with weighted graphs like this one. Instead of the fringe being a regular old queue, we will instead have a priority queue, which removes vertices according to which one has the shortest path from the starting vertex. Since we want the path with smallest weight, we will have a minimum priority queue.
Each entry in the fringe will be a vertex name, plus two extra pieces of
information: the parent node, and the path length. We'll write these as
a tuple; for example (C, B, 15) means "the path to C that goes
through B has length 15".
Besides the fringe data structure, we also have to keep track of which nodes have been "visited", and what is the "parent" of each visited node, just like with BFS. Both of these can be maps; probably the same kind of map (either balanced tree or hashtable) that stores the vertices of the graph itself.
OK, let's get back to our example from above, and run Dijkstra's algorithm to find the shortest path from A to H. You might want to open that graph up in a new tab or print it out so you can follow along.
To run through this example, we'll look at the "state" of our
three data structures visited, parents,
and fringe, at each step along the way. Here's the initial
state:
visited: parents: fringe: (A, null, 0)
- Remove
(A, null, 0)from the fringe.
We mark vertex A as visited and set its parent.
Then we add 2 new fringe entries for each of A's neighbors.
visited: A parents: A->null fringe: (B,A,5), (C,A,7)
- Remove
(B, A, 5)from the fringe.
Vertex B gets "visited", its parent is set to A, and its 4 neighbors are added to the fringe.
Notice: I'm not writing the fringe in order. It's a minimum priority queue, so things will be removed according to the shortest distance first; but the actual order will depend on what data structure gets used, e.g., a heap.visited: A, B parents: A->null, B->A fringe: (C,A,7), (A,B,10), (C,B,15), (D,B,9), (G,B,22)
Also notice: The distances (priorities) stored with each node in the fringe correspond to the total path length, not just the last edge length. Since the distance to the current node B is 5, the distances to B's neighbors A, C, D, G are 5+5, 5+10, 5+4, and 5+17. - Remove
(C, A, 7)from the fringe.
Vertex C gets visited, its parent is A, and its 4 neighbors go in the fringe.visited: A, B, C parents: A->null, B->A, C->A fringe: (A,B,10), (C,B,15), (D,B,9), (G,B,22), (A,C,14), (B,C,17), (D,C,10), (E,C,22)
- Remove
(D, B, 9)from the fringe.
Notice: This vertex is removed next because it's a min-priority queue.
Vertex D gets visited, its parent is B, and its 3 neighbors go in the fringe.visited: A, B, C, D parents: A->null, B->A, C->A, D->B fringe: (A,B,10), (C,B,15), (G,B,22), (A,C,14), (B,C,17), (D,C,10), (E,C,22), (B,D,13), (C,D,12), (E,D,10)
- Remove
(A, B, 10)from the fringe.
Nothing happens because A is already visited.visited: A, B, C, D parents: A->null, B->A, C->A, D->B fringe: (C,B,15), (G,B,22), (A,C,14), (B,C,17), (D,C,10), (E,C,22) (B,D,13), (C,D,12), (E,D,10)
- Remove
(D, C, 10)from the fringe.
Nothing happens because D is already visited.visited: A, B, C, D parents: A->null, B->A, C->A, D->B fringe: (C,B,15), (G,B,22), (A,C,14), (B,C,17), (E,C,22), (B,D,13), (C,D,12), (E,D,10)
- Remove
(E, D, 10)from the fringe.
Vertex E gets visited, its parent is D, and its 3 neighbors go in the fringe.visited: A, B, C, D, E parents: A->null, B->A, C->A, D->B, E->D fringe: (C,B,15), (G,B,22), (A,C,14), (B,C,17), (E,C,22), (B,D,13), (C,D,12), (C,E,25), (D,E,11), (F,E,13)
- Remove
(D, E, 11), then(C, D, 12), then(B, D, 13), from the fringe.
Nothing happens because E, C, and B are visited already.fringe: (C,B,15), (G,B,22), (A,C,14), (B,C,17), (E,C,22), (C,E,25), (F,E,13)
- Remove
(F, E, 13)from the fringe.
Vertex F gets visited, its parent is E, and its 2 neighbors go in the fringe.visited: A, B, C, D, E, F parents: A->null, B->A, C->A, D->B, E->D, F->E fringe: (C,B,15), (G,B,22), (A,C,14), (B,C,17), (E,C,22), (C,E,25), (E,F,16), (G,F,15)
- Remove
(A, C, 14), then(C, B, 15), from the fringe.
Nothing happens because A and C are visited already.fringe: (G,B,22), (B,C,17), (E,C,22), (C,E,25), (E,F,16), (G,F,15)
- Remove
(G, F, 15)from the fringe.
Vertex G gets visited, its parent is F, and its 4 neighbors go in the fringe.visited: A, B, C, D, E, F, G parents: A->null, B->A, C->A, D->B, E->D, F->E, G->F fringe: (G,B,22), (B,C,17), (E,C,22), (C,E,25), (E,F,16), (B,G,32), (F,G,17), (H,G,30), (I,G,19)
- Remove
(E, F, 16), then(B, C, 17), then(F, G, 17), from the fringe.
Nothing happens because E, B, and F are visited already.fringe: (G,B,22), (E,C,22), (C,E,25), (B,G,32), (H,G,30), (I,G,19)
- Remove
(I, G, 19)from the fringe.
Vertex I gets visited, its parent is G, and its 2 neighbors go in the fringe.visited: A, B, C, D, E, F, G, I parents: A->null, B->A, C->A, D->B, E->D, F->E, G->F, I->G fringe: (G,B,22), (E,C,22), (C,E,25), (B,G,32), (H,G,30), (G,I,23), (H,I,21)
- Remove
(H, I, 21)from the fringe.
Vertex H gets visited, its parent is I.We can safely stop the search here because all the nodes have been visited. Of course, it would be fine to add the neighbors of H to the fringe and then remove everything; nothing would happen because everything is already visited.visited: A, B, C, D, E, F, G, I, H parents: A->null, B->A, C->A, D->B, E->D, F->E, G->F, I->G, H->I
Hooray! We did it! We found the shortest paths from A to H, which can
be retraced by following the parent pointers backwards:
H-I-G-F-E-D-B-A. This path has many hops, but the shortest
possible total length of 21.
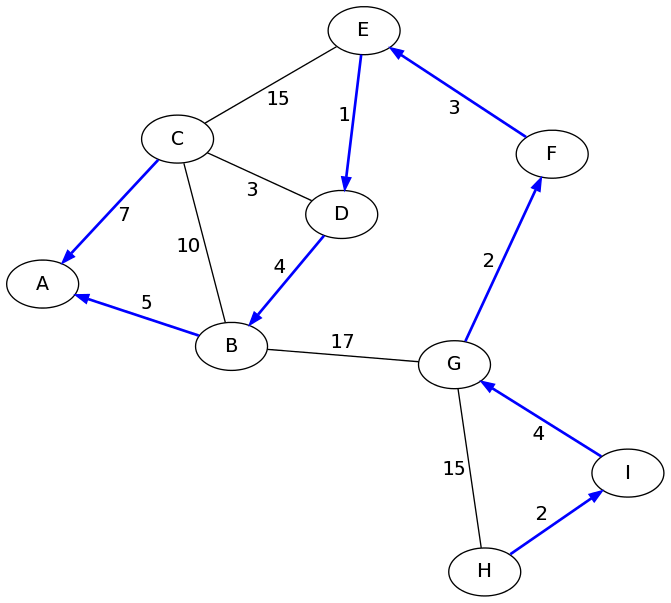
In fact, we have found all of the shortest paths from A. The parent pointers encode a tree that gives the fastest path from A to any other node in the graph. Here they are drawn in blue:
Beginning of Class 32
2 Dijkstra's Runtime
Here's some pseudocode for the algorithm we just learned:
1 2 3 4 5 6 7 8 9 10 | function dijkstra(G, start): initialize fringe, parents, visited add (start, null, 0) to fringe while fringe is not empty: (u, par, len) = fringe.removeMin() if u is not visited: mark u as visited set parent of u to par for each edge (u,v,w) in G.neighbors(u): add (v, u, len+w) to fringe |
Actually, if you remove the stuff about the weights and priorities, you could use exactly the same pseudocode for DFS or BFS, depending only on the data structure of fringe.
How long does Dijkstra's take? Well, it's going to depend on what data structures we use for the graph and for the priority queue. Let's go through each of the important (i.e., potentially most costly) steps in the algorithm:
- Calling removeMin() on line 5:
The number of times this happends depends on the maximum size of the fringe. Unless we do something fancy, the fringe size is at most \(m\), so the removeMin() method gets called at most \(m\) times. - Calling neighbors() on line 9:
This happens once each time a node is visited, so it happens at most \(n\) times in total. - Adding to the fringe on line 10:
This happens once for each outgoing edge of each node, which means \(m\) times total.
So to figure out the running time for Dijkstra's, we have to fill in the blanks in the following formula: \((\text{fringe size})\times(\text{removeMin cost}) + n\times(\text{neighbors cost}) + m\times(\text{fringe insert cost}) \)
For example, if the graph is implemented with a hashtable and an adjacency list, and the fringe is a heap, the total cost is \(O(m\log m + n + m\log m) = O(n + m\log n).\) (Note that we can say \(\log m \in O(\log n)\) since \(m\) is \(O(n^2)\) for any graph.)
That's pretty good! Remember that the best we can hope for in any graph algorithm is \(O(n+m)\), so \(O(n+m\log n)\) is not too far off from the optimal.
What about another data structure for the priority queue? We should consider the "simple" choices like a sorted array or an unsorted linked list. Most of the time, those simple options aren't better than the "fancy" option (i.e., the heap). But that's not the case this time. If we use an unsorted array for the priority queue, and eliminate duplicates in the fringe so that the fringe size is never greater than \(n\), the total cost is \(O(n^2 + n\times(\text{neighbors cost}) + m) = O(n^2)\).
(To see why that's true, remember first that inserting in an unsorted array is \(O(1)\), whereas removing the smallest item is \(O(n)\). Second, the cost of neighbors() for any graph data structure is never more than \(O(n)\). Third, since the number of edges in any graph is \(O(n^2)\), you can simplify \(O(n^2 + m)\) to just \(O(n^2)\).)
What all this means is that if we use the a certain graph data structure (adjacency list with hashtable) and a heap, the running time is \(O(n + m\log n)\). But if we use ANY graph data structure with an unsorted array, the running time is \(O(n^2)\). We can't say for sure which option is better; if \(m\) is closer to \(n\) (i.e., a sparse graph), then the \(O(n + m\log n)\) would be smaller. But if \(m\) is closer to \(n^2\) (i.e., a dense graph), then \(O(n^2)\) is a better running time.
As always, it's more important that you are able to use the procedure above to decide the running time of Dijkstra's algorithm for any combination of data structures, rather than memorizing the running time in a few particular instances.
Beginning of Class 33
3 Floyd-Warshall
Consider the "sledding hill" problem: I have a map of Annapolis with the elevation difference of each road segment marked, and I want to find the path &emdash; starting and ending at any spot &emdash; that gives the greatest total elevation difference. In such a situation, Dijkstra's algorithm has two shortcomings:
- Dijkstra's only works with non-negative edge weights. If the weights of edges can be positive or negative (such as elevation changes), Dijkstra's is no longer guaranteed to find the shortest path the first time it visits a node, and so cannot be used in such situations.
- Dijkstra's only finds the shortest paths from a single starting point. If we are interested in the shortest paths that could start and end anywhere, we would have to run Dijkstra's algorithm \(n\) times, starting at every possible position.
What we're talking about here is called the All-Pairs Shortest Paths Problem: finding the shortest paths between every possible starting and ending point in the graph, in one shot. For now, we'll just consider the slightly simpler problem of finding the lengths of all these shortest paths, like the height of the best sledding hill. (Later we'll say how you could also get the paths themselves.)
First think about how we would store the output. There are \(n\) starting points and \(n\) ending points, so that means \(n^2\) shortest path lengths - let's put 'em in a \(n\times n\) matrix! This "shortest paths matrix" will be similar to the adjacency matrix, except that instead of storing just single edges we have all the shortest paths.
The algorithm that we are going to learn for this problem is called the Floyd-Warshall algorithm, which is named after 2 people but actually has at least four different claimants to that title. This algorithm starts with the adjacency matrix of a graph, which we will gradually turn into the shortest paths matrix. (If your graph is stored in an adjacency list, you would have to convert it to an adjacency matrix first.)
The idea of the algorithm is that, at step \(i\), we will have the lengths of all shortest paths whose intermediate stops only include the first \(i\) vertices. Initially, when \(i=0\), we have just the single-edge paths (with no indermediate stops), and at the end when \(i=n\) we will have the shortest paths with any number of intermediate stops. Cool!
To see how this works, let's go to an example:
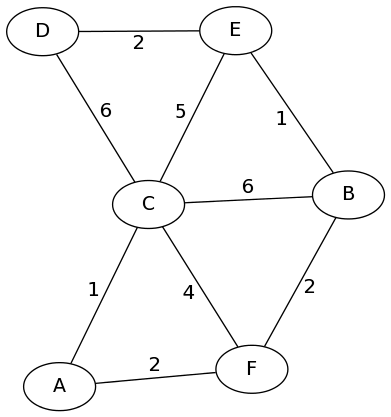
We start with the adjacency matrix for this graph:
\( \newcommand{\I}{\infty} \newcommand{\C}[1]{{\color{BlueViolet}{\mathbf{#1}}}} \)This is essentially all the shortest path if no intermediate locations are allowed. The first thing to do, is allow node A to be an intermediate vertex in any of these paths. As you can see, that's only going to (possibly) affect the shortest path from C to F. In deciding whether it does, we consider two options: the current shortest path from C to F (length 4), or the sum of the paths to C to A (length 1) plus the path from A to F (length 2). In this case, the sum is smaller, so that entry will be updated.
This update process can be described in pseudocode as follows:
1 2 3 4 5 | updateShortest(Matrix, Source, Dest, NewStop): current = Matrix[Source][Dest] newPossibility = Matrix[Source][NewStop] + Matrix[NewStop][Dest] if newPossibility < current then Matrix[Source][Dest] = newPossibility |
In this example, the path from C to F (and F to C, since the graph is undirected) gets improved to length 3:
Next, we let B be an intermediate point in any path. What this means is that
we run the updateShortest function on every possible starting/ending
point combination in the matrix, looking for anywhere where stopping at B gives
a shorter path. Once again, only a single path actually gets update here (E to F).
But notice that this time we do better than just finding a slightly better path,
B connects two vertices that otherwise would not be reachable, making the
"shortest path length" go from infinity down to 3:
The next "intermediate vertex" allowed is C. This time, we get a whole bunch of updates throughout the matrix (changes shown in purple):
Notice that one of the updated paths (D to F) used the first update (faster path from C to F) as part of its own shortest path, to get a length-9 path from D to F that goes through C and through A.
The next step is to update paths to allow the next vertex, D. But if you did this, you'd notice that none of the paths actually get updated. That's okay! We move on to the next intermediate vertex, E. Two paths get shorter by going through E:
Finally, we shorten three paths by allowing them to go through the last node, F:
Now this matrix stores the shortest path lengths between eny pair of vertices in the original graph. Check it if you don't believe me!
The only detail we've glossed over is how you would actually recover these shortest paths. The answer is that you have parent pointers, just like we did for Dijkstra's algortihm. Except, instead of just storing \(n\) parent pointers indicating how to get back to the single starting point, we will need to store \(n^2\) parent pointers for how to get back from any point to any possible starting point, in the shortest way! Naturally, we would use another matrix to store such pointers.
The pseudocode for Floyd-Warshall looks like this:
1 2 3 4 5 6 | FloydWarshall(G): Matrix = copy of G's adjacency matrix for each Intermediate in G.getVertices(): for each Start in G.getVertices(): for each End in G.getVertices(): updateShortest(Matrix, Start, End, Intermediate) |
This shows the real power of Floyd-Warshall's algorithm: its simplicity. It's just three nested for loops! \(O(n^3)\) running time.