Unit 3: ADTs and LSQs
Credit: Gavin Taylor for the original version of these notes.
In this unit, we are going to learn about Abstract Data Types (ADTs) and our first three ADTs: Lists, Stacks, and Queues - i.e., LSQs. Besides being the first data structures we learn, these are also really important data structures that get used over and over again in many different computing problems. They will come up in future parts of this class as well as future classes that you take for your CS or IT degree.
Beginning of Class 8
1 Our first ADT: List
Abstract Data Types
Allegedly, this course is about Data Structures. In actuality, it is about Abstract Data Types (ADTs) and their implementation with Data Structures. An ADT is a description of an interface, and the data structures are how we make them work. For instance, last semester, we built a Queue. A Queue is an ADT; the linked list is the data structure.
Lists
Our first ADT is a List. A List is a container that holds data in some order, and can perform the following methods:
- get(i) - return the data at the i-th place in the list.
- set(i,e) - return the i-th piece of data, and also replace it with e.
- add(i,e) - insert e in the list at location i. All data with locations greater than i are shifted to a location one greater.
- remove(i) - remove and return the data at i. Shift all data at higher indices down.
- size() - return the number of elements in the list.
This is all an ADT is! Any way of making this work, no matter how stupid or slow, still means it is a list. However, implementing it with different data structures gives us different run times.
So how would we implement this? Perhaps, arrays or linked lists. Presumably, you could implement all four of those methods with both, and analyze the run times.
Iterators
Assume we have a list aList, and we have the following code:
1 2 | for (int i = 0; i < n; i++) aList.get(i); |
What is the runtime if our list is implemented with an array? O(n), right? What if it's implemented with a LL? Well, each get is O(n), and we've got n of them, so it's \(O(n^2)\). That's stupid! This should clearly be O(n).
We can get this to be O(n) by using an "iterator," an object which keeps track of the last element it looked at, and can return the next one. In this way, we can jump from element to element, doing a \(O(1)\) update \(n\) times. We're not going to spend any time implementing Iterators in Java, but suffice to say they exist ("Iterator" is an interface). Just so you'll believe me, an example of an Iterator for a linked list of strings like in HW3 is below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | import java.util.Iterator; public class LL { private class Node { String data; Node next; /* ... more Node stuff here ... */ } public class LLIterator implements Iterator<String> { private Node current; public LLIterator(Node start) { this.current = start; } public boolean hasNext() { return this.current != null; } public String next() { String toRet = this.current.data; this.current = this.current.next; return toRet; } public void remove() { throw new UnsupportedOperationException(); } } private Node first; /* ... more LL stuff here ... */ public Iterator<String> iterator() { return new LLIterator(this.first); } } |
Did you use a foreach loop last semester to work with Java's ArrayLists or LinkedLists? Then you used an Iterator, and just didn't know it!
A note about size
You can pretty easily imagine how size() is implemented
for an array-based list - you just get the length of the array. But for
a linked list, we would have to iterate over the whole list, taking \(O(n)\),
right?
Well, all that work could be easily avoided by storing one extra
little piece of data in the Linked List class - namely, an int
for the current size of the list. This value would be updated on each
add or remove operation, and returned by each
a call to size().
There is something subtle but important about why this is okay:
An ADT implementation is allowed to store extra data besides whatever
information the ADT itself specifies. In the case of a List, the ADT just
specifies that you are storing an ordered sequence of elements. It says nothing
about storing the size. But your data structure is allowed to store the size,
in order to make the size() operation more efficient! The key
is actually that the total storage is still the same in terms of big-O, since
\(n+1 \in O(n)\).
So here's what we have so far:
| Array | Linked List | |
|---|---|---|
| get(i) | O(1) | O(n) |
| set(i,e) | O(1) | O(n) |
| add(i,e) | O(n) | O(n) |
| remove(i) | O(n) | O(n) |
| for all i, get(i) | O(n) | O(n) |
| size() | O(1) | O(1) |
Beginning of Class 9
A better Array implementation of List?
Remember what linked lists are faster at than arrays? That's right, adding to the beginning or the end of the list! With linked lists this is \(O(1)\) but arrays always take \(O(n)\) because the entire array has to be resized and copied. Well, there's not much we can do about adding to the beginning of an array, but it is possible to make adding to the end of an array-based list faster.
Let's use the scheme that every time we run out of room on our array, we double the size of the array. Will we have lots of unused indices? Yup. But, if our biggest number of elements in the list is n, the most memory we'll use is 2n. And, while that might hurt, at least that's still O(n). (Yup! We can (and do) use Big-O in reference to memory, too!)
So, OK, we only resize every time we actually fill this too-big array. Isn't the worst case still O(n)? Well, sort of. For the first time, our "number of operations as a function of n" function isn't smoothly increasing; instead, it's spiky. This is because almost all of the time, adding to the end is O(1). However, every now and then, it's O(n). See:
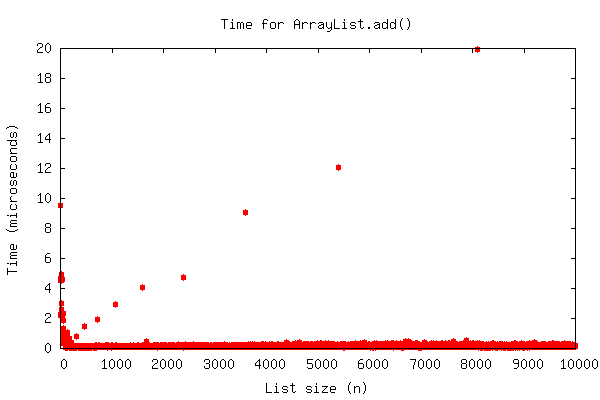
If you drew a line threw those little red "outlier" dots, it'd be a straight line; \(O(n)\). But almost all the dots are right there at the bottom, \(O(1)\), not increasing at all even with thousands of elements in the array.
What we'd like to say is that those \(O(n)\) dots don't ultimately matter, and the real cost is \(O(1)\). Amortized analysis is what lets us say this and still be mathematically correct.
Pretend you have a business. Every 10 years, you have to buy a $100,000 machine. You have two ways you could consider this; either, every ten years you lose massively, having to pay $100,000, or every year you put aside $10,000 to be used later. This is called amortizing the cost. We can do the same thing here.
Let's assume assigning one element to an array is 1 operation. Again, if we double the size of the array every time we need more space, starting with an array of size one, we would get the following series of costs when adding 17 elements to an initially-empty array:
1 2 3 1 5 1 1 1 9 1 1 1 1 1 1 1 17
The reason is that when the size reaches \(1, 2, 3, 5, 9, 17\), which is 1 more than each power of 2, we have to allocate a new array and copy everything over. So those are the "outlier", expensive additions. But all the other additions are cheap; they just involve copying a single element.
But we can amortize these expensive additions over the previous "cheap" ones! Check it out:
| Size | 1 | 2 | 3 | 5 | 9 | 17 |
| Actual costs | 1 |
1,2 |
1,2,3 |
1,2,3,1,5 |
1,2,3,1,5,1,1,1,9 |
1,2,3,1,5,1,1,1,9,1,1,1,1,1,1,1,17 |
| Amortized | 1 |
3,0 |
3,3,0 |
3,3,3,3,0 |
3,3,3,3,3,3,3,3,0 |
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,0 |
Noticing the theme? No matter how big our stack becomes, the amortized cost of a single push never gets bigger than 3. So, the cost of a push, even with resizing the array, is O(1).
Another way of putting this is that the sum total cost of a series of \(n\) additions onto the end of an initially-empty array is \(O(n)\). In fact, if we take the same graph as above and plot the running sum instead of the individual cost of each operation, the fact that this line is \(O(n)\) becomes fairly obvious:
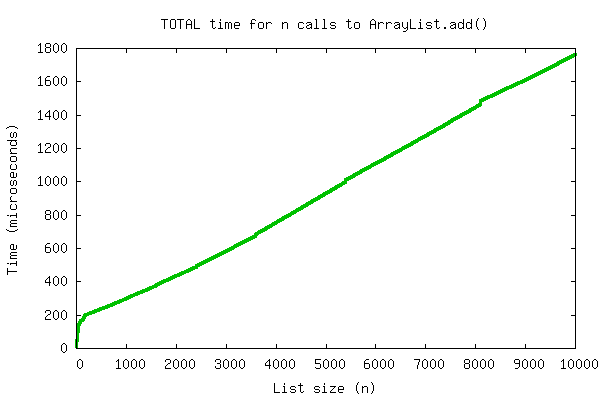
As you may already know, this is in fact exactly how Java's ArrayList
class works. Using similar ideas they can also remove from the end of an
ArrayList in \(O(1)\) amortized time, and guarantee that the space usage is
kept at \(O(n)\). In fact, the previous graphs came from timing Java's own
ArrayList!
There is one additional problem with the doubling-size array implementation
of a List: the size of the array no longer matches the size of the list! So
just like with linked lists, we have to store an extra int for the
"actual" size of the list, which will always be ≤ the size of the array.
Again, this keeps the storage as \(O(n)\) and so it's okay.
2 Stacks
Stacks
Our second ADT is the Stack. We're pretty familiar with Stacks already, so this might not be so hard. Stacks work like a stack of plates: you only add plates onto the top of the stack, and you only remove stacks from the top of the stack. This makes them a LIFO (last-in-first-out).
The methods of a stack are:
- push(e) - Add element e to the top of the stack.
- pop() - Take the top element off the top of the stack, and return it.
- peek() - Return the top element of the stack, without altering the stack.
Let's consider an example. On the left column of this table, I will have some commands. In the middle, I'll put what is returned, if anything. On the right, I'll put the state of the stack, with the top of the stack on the left.
| Command | Returned Value | Stack |
|---|---|---|
| push(3) | - | 3 |
| push(5) | - | 5 3 |
| pop() | 5 | 3 |
| peek() | 3 | 3 |
| push(4) | - | 4 3 |
| peek() | 4 | 4 3 |
| pop() | 4 | 3 |
| pop() | 3 |
Implementation with Different Data Structures
Implementation with Linked Lists should seem relatively easy to you; if "first" refers to the top element of the stack, then push() is just an add-to-front, pop() is a remove-from-front, and peek is just return first.getData(); (modulo error checking for an empty stack, of course).
This means that for stacks implemented by linked lists, all three methods can be run in O(1) time. Great!
What about arrays? Well, if we used a "dumb" array, each push and pop would cost \(O(n)\) because of the need to copy the entire contents each time. But as we saw above with ArrayList, we can be smart about this and leave some empty space in the array, doubling it when necessary. You could technically also shrink the array (halving when necessary) in pop(), but that makes everything more cumbersome, so we'll assume the resizings only happen during push().
Here's how the two implementations stack up (get it?):
| Linked List | Array | |
|---|---|---|
| push() | O(1) | O(1) amortized |
| pop() | O(1) | O(1) |
| peek() | O(1) | O(1) |
Usefulness of Stacks
OK, so stacks are fast! What can we do with them?
- Reverse stuff - pushing everything on, and then popping it all off puts it in reverse order.
- Maze solving - every time you come to a junction, push it on the stack. When your decision doesn't work out, pop to the last junction, and go the other way. If there are no more possible directions, pop again.
- For more complex uses of stacks, stay tuned...
Beginning of Class 10
3 Queues
Queues
We know Queues well from IC211. If a Stack is a LIFO (Last-In First-Out), then a Queue is a FIFO (First-In First-Out). In other words, things come out in exactly the same order they went in.
Think about a line for the checkout counter at the grocery store (after all, "queue" is British for "line"). People can only join the line at the end, and only leave the line at the front. In between, they never switch order.
The methods a Queue must have are:
- enqueue(e) - Add an element to the back of the Queue
- dequeue() - Remove and return the front element of the Queue
- peek() - Return, but do not remove, the front element of the Queue
Implementation
Implementation with a Linked List is fairly straightforward. Enqueue is just an add-to-back, which is O(1) if we have a pointer to the last link in the Linked List. Dequeue is just a remove-from-front, which, again, is O(1). peek is Dequeue but easier, so it is also O(1).
Implementation with an array requires a bit more bookkeeping. Every time we dequeue, we don't want to shift everything down so that the first element remains at the front of the array, that would be expensive and silly. So, we keep two values: front, and size. Front the index of the first element of the queue, and size indicates the number of elements in the queue. As elements are enqueued and dequeued, the queue can wrap around the end of the array, back to the beginning of the array if appropriate. If the array fills up, we double the size of the array, as with the stack. So, enqueue is an AMORTIZED O(1), just like push. dequeue and peek are also trivially O(1).
So, we resize our array when size==array length. Aside from that, how do we do find the index of the first open space, when we're allowed to wrap around? Well, if our array was infinitely long, or no wrapping was required, the first open index would be at front+size. Since we're wrapping, it's at (front+size)%array.length. After inserting your element, you then have to increment size.
To dequeue, we want to indicate that the element currently at index "front" is now eligible for a new element. So, we increment front (wrapping back around to 0 if need be), and decrement size.